Discovery: Gathered evidence from support tickets and partner complaints. Found that the legacy component had not been touched since early platform days and was creating compounding issues.
Research: Conducted card sorting with operators to understand mental models. Tested three approaches: search-first, browse-first, and hybrid. Browse-first won for this use case.
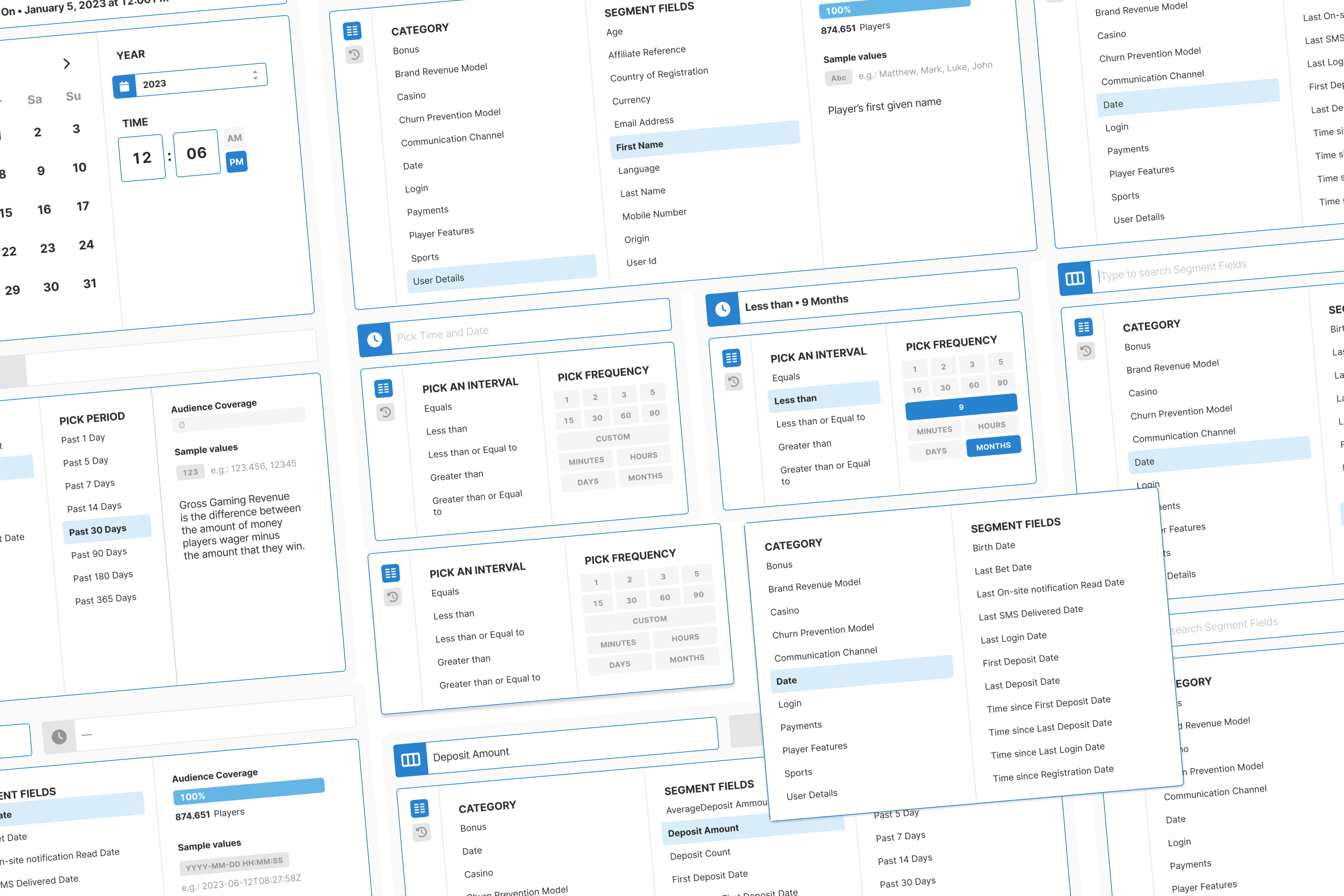
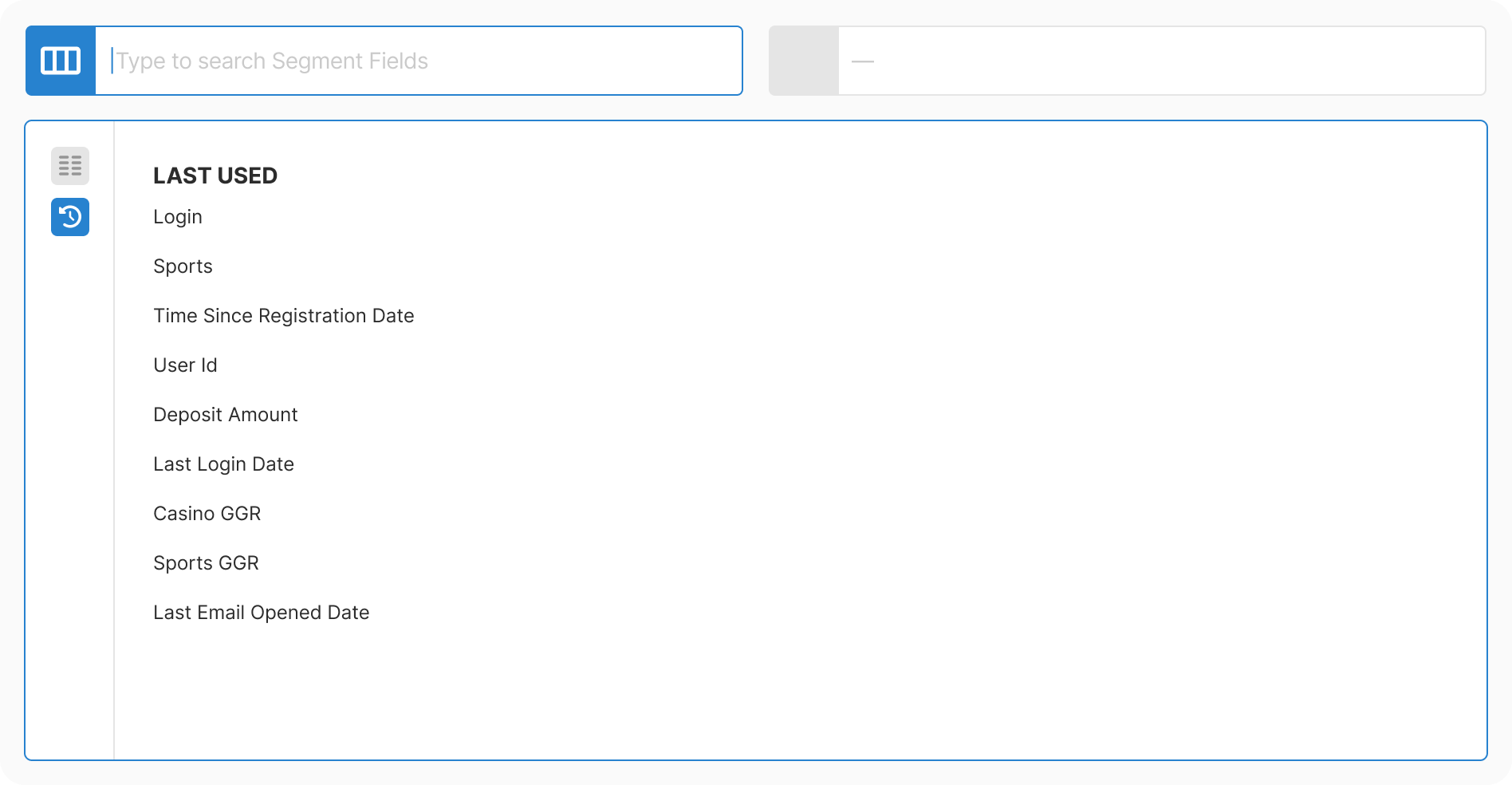
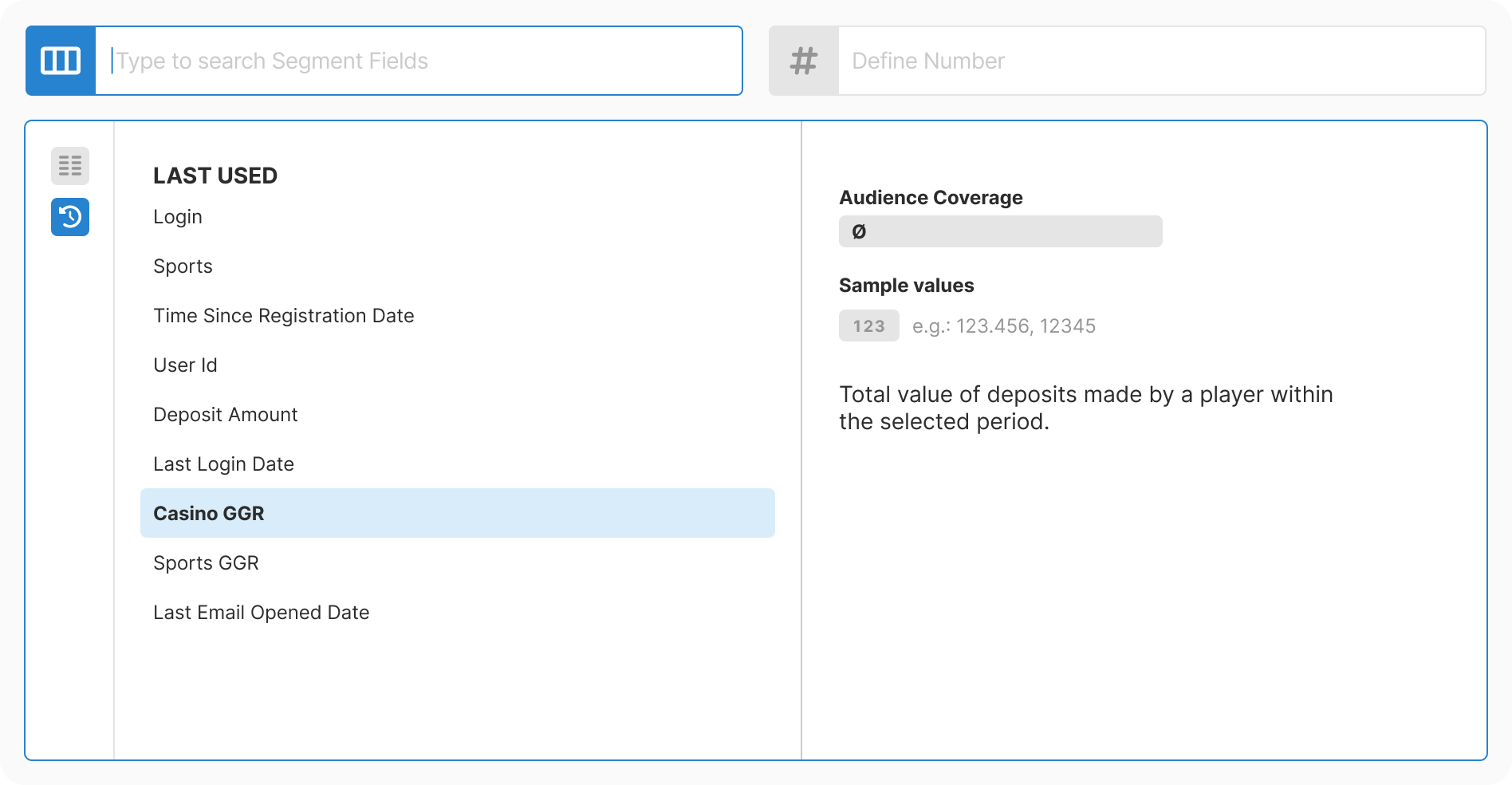
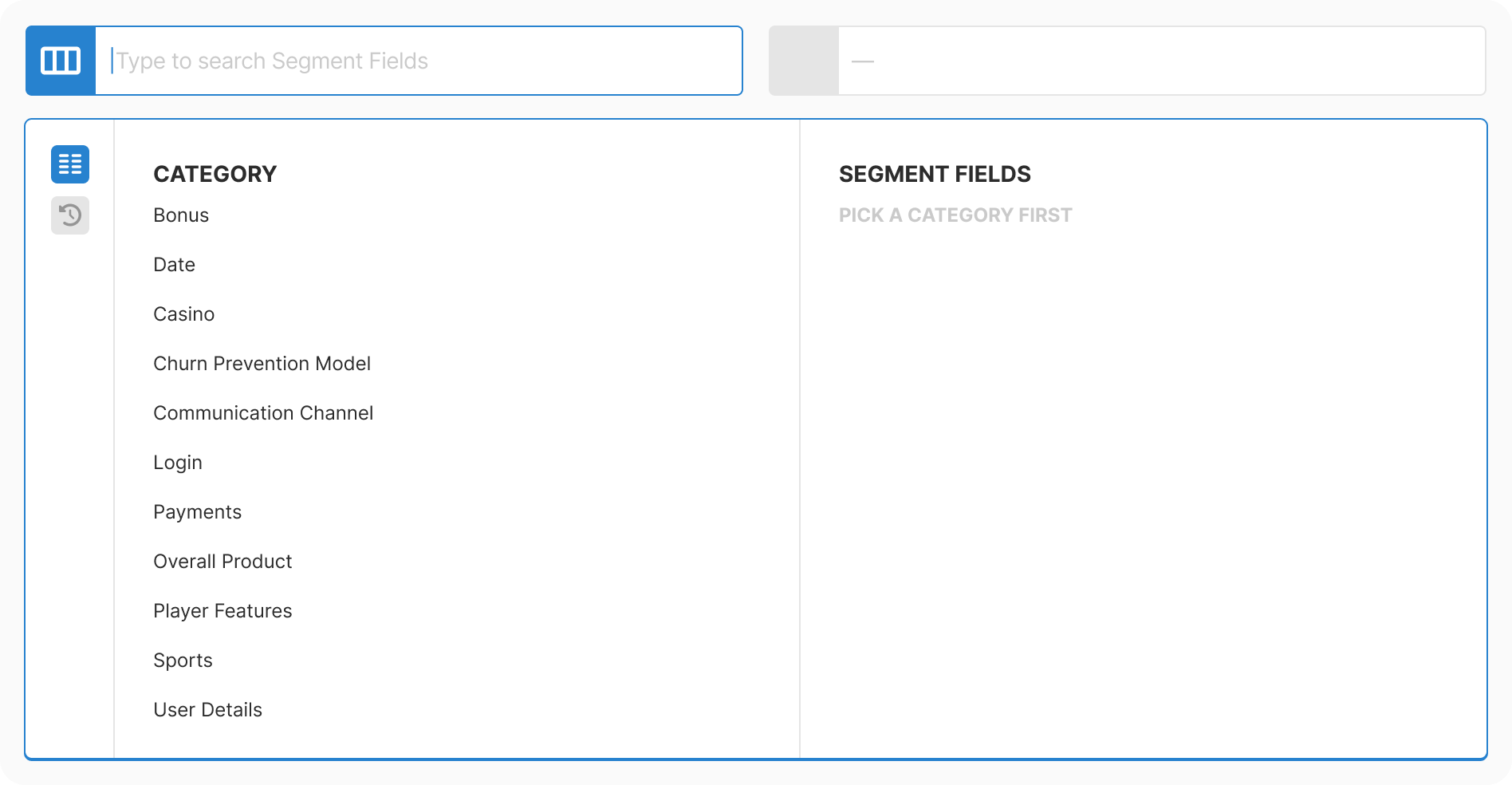
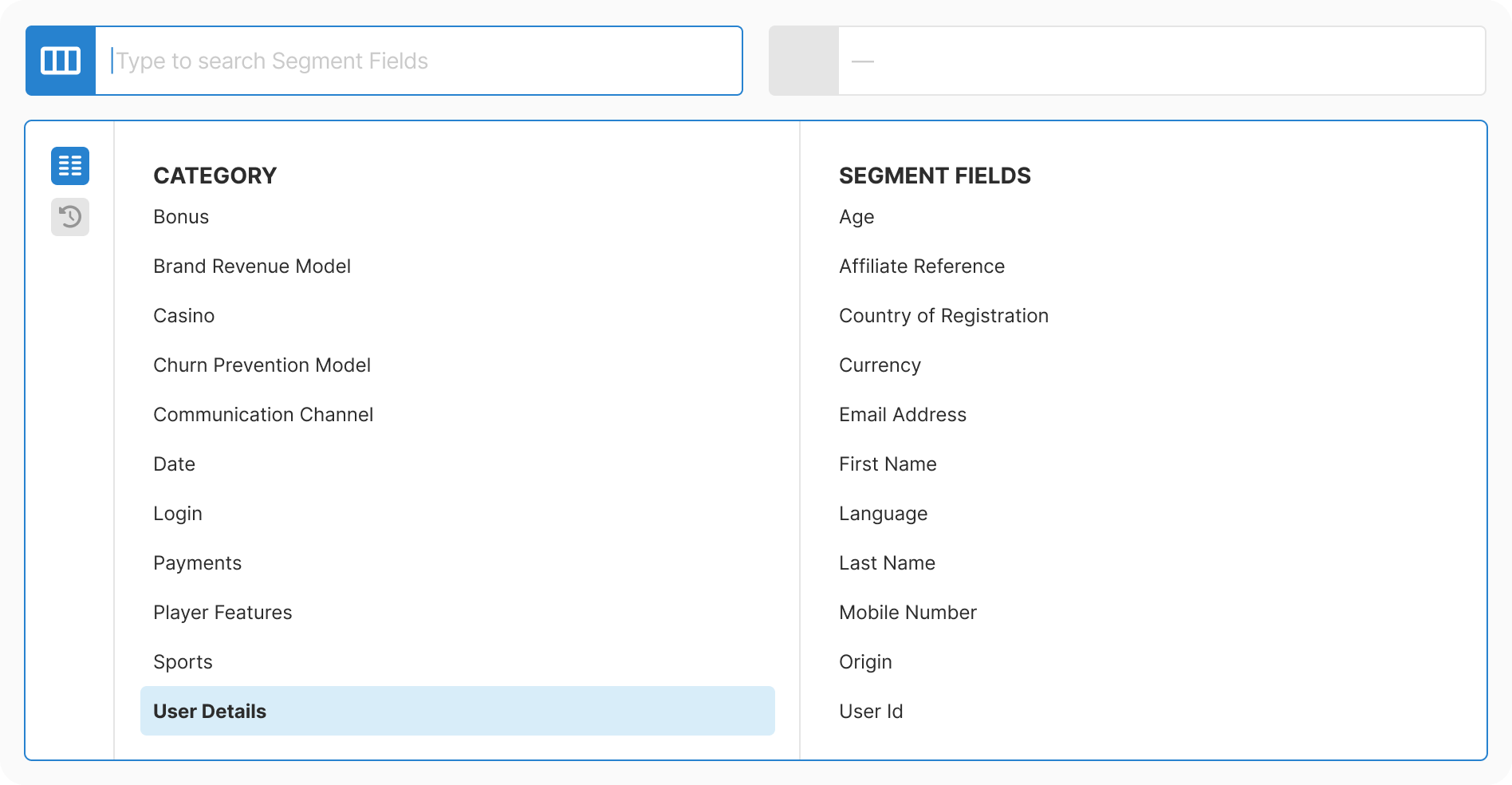
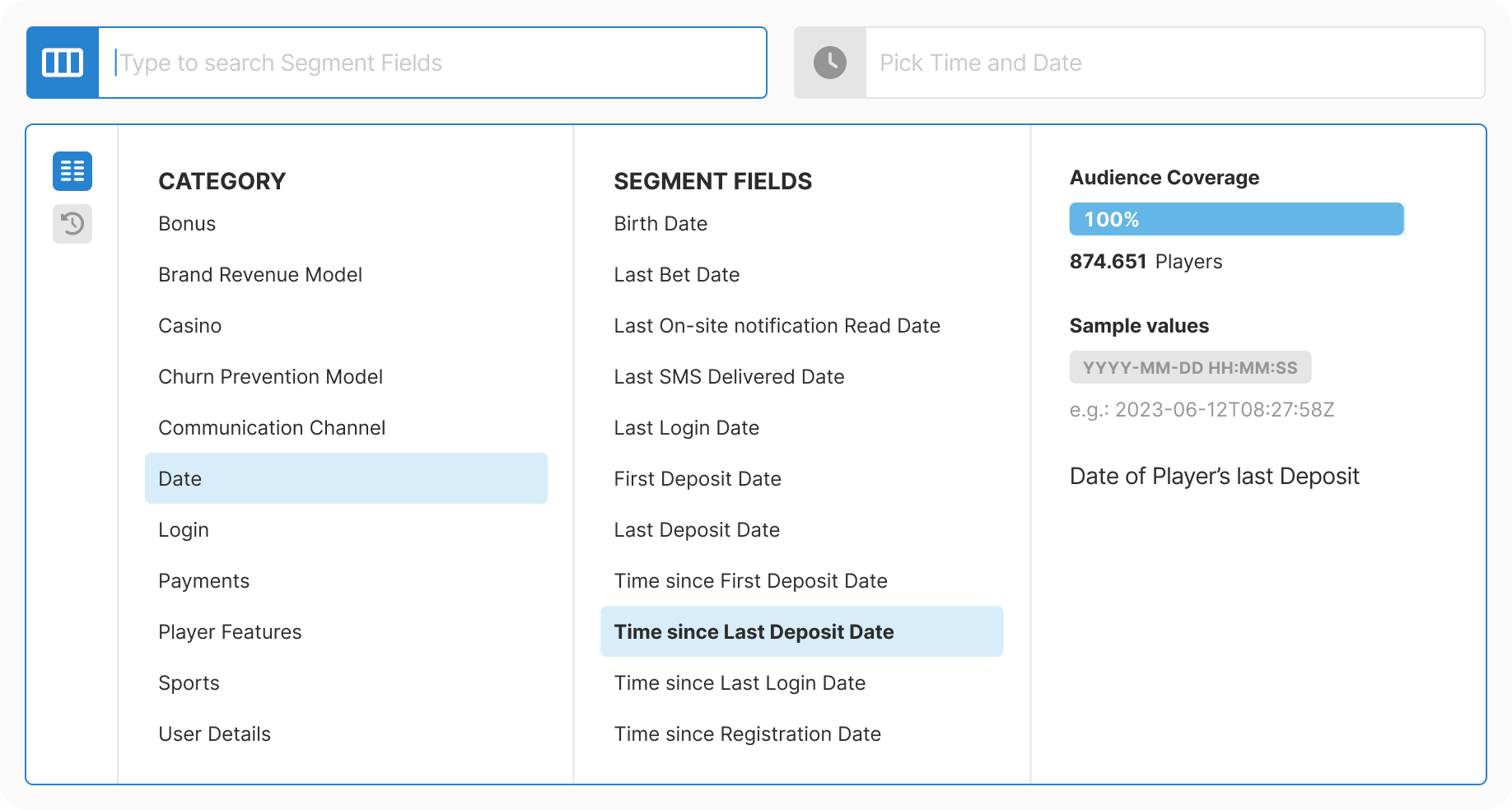
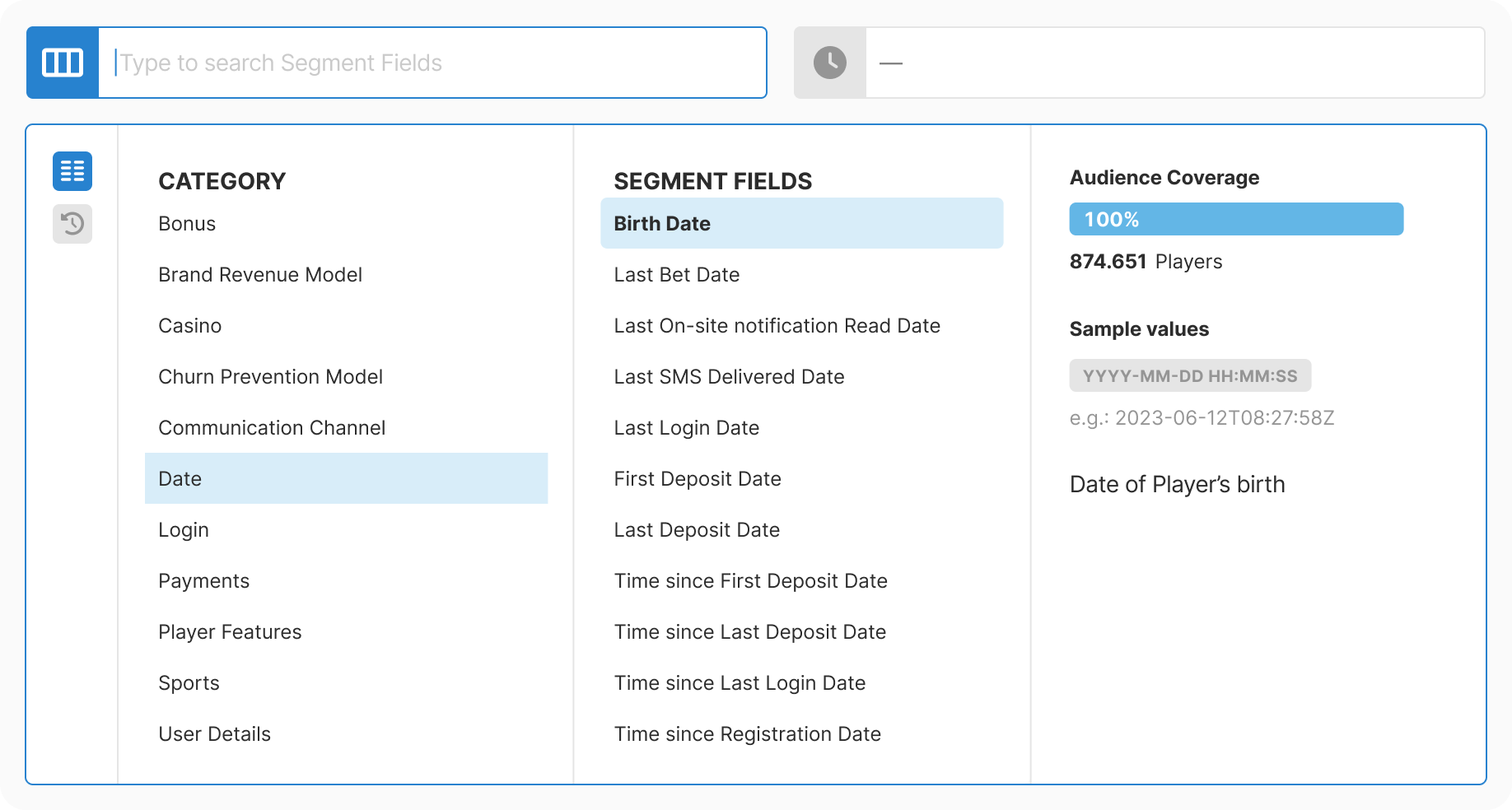
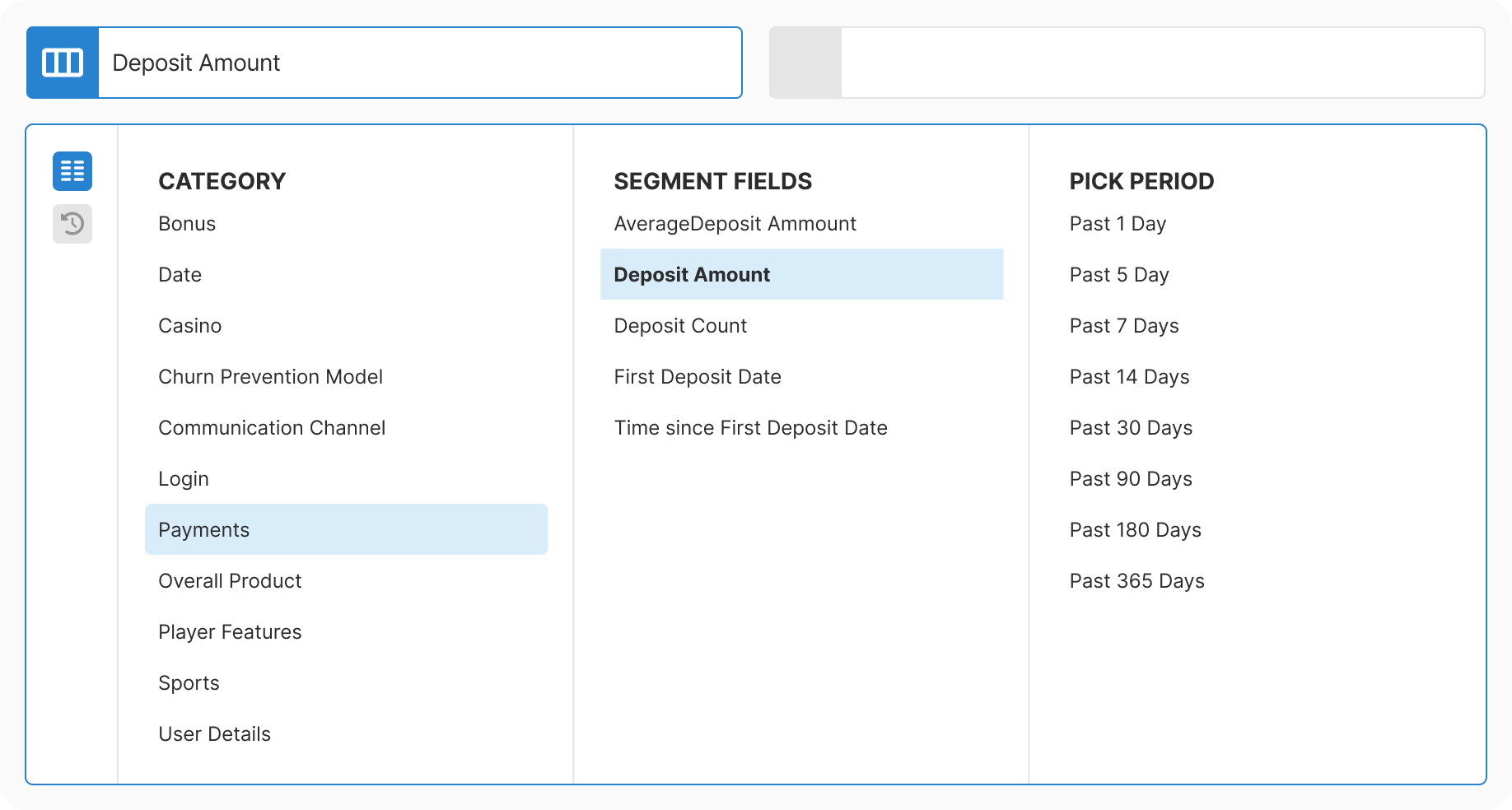
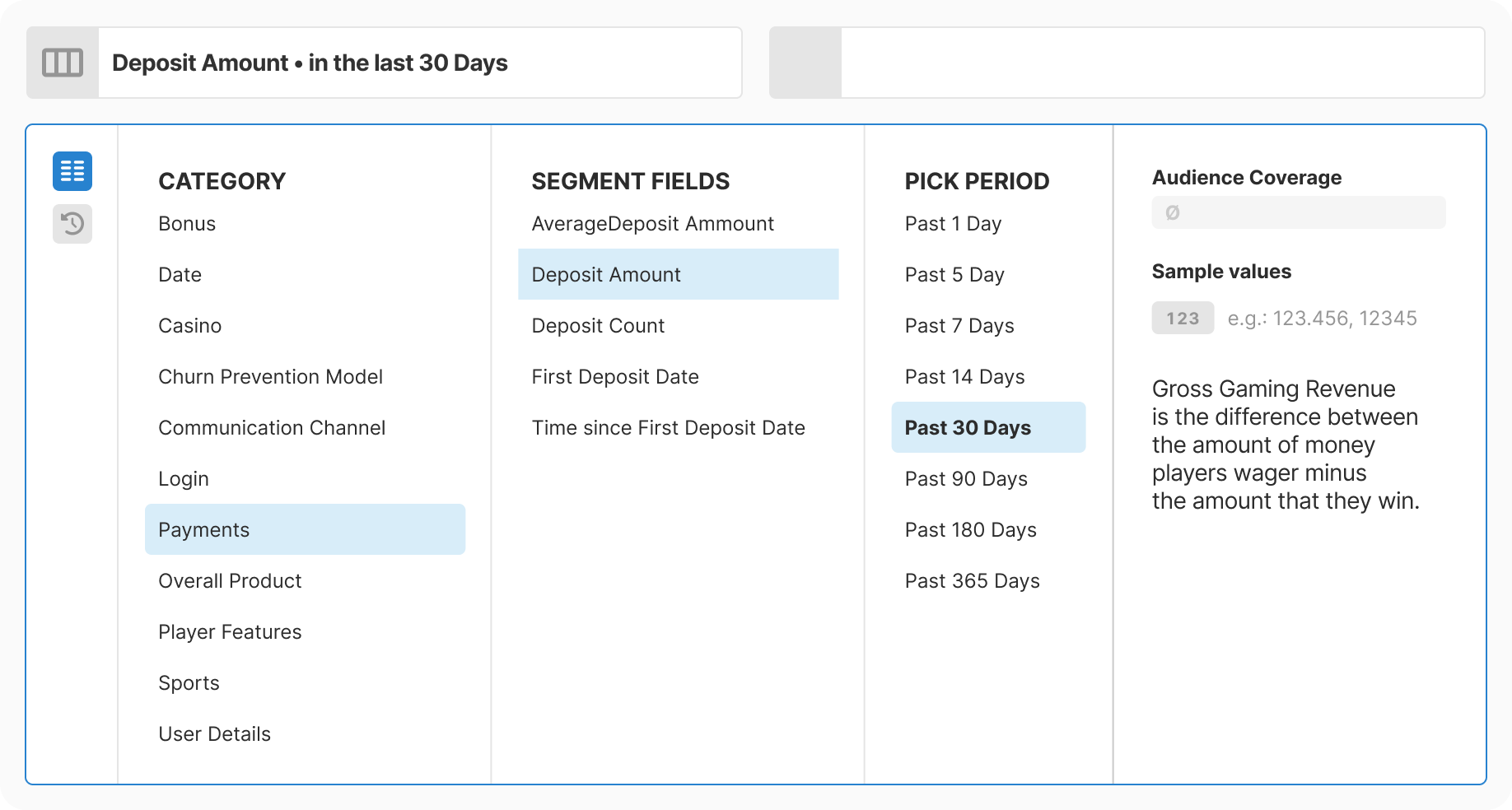
Taxonomy: Mapped 200+ fields into 11 logical categories. Combined database extraction with manual enrichment. Allowed intentional duplicates where findability improved.
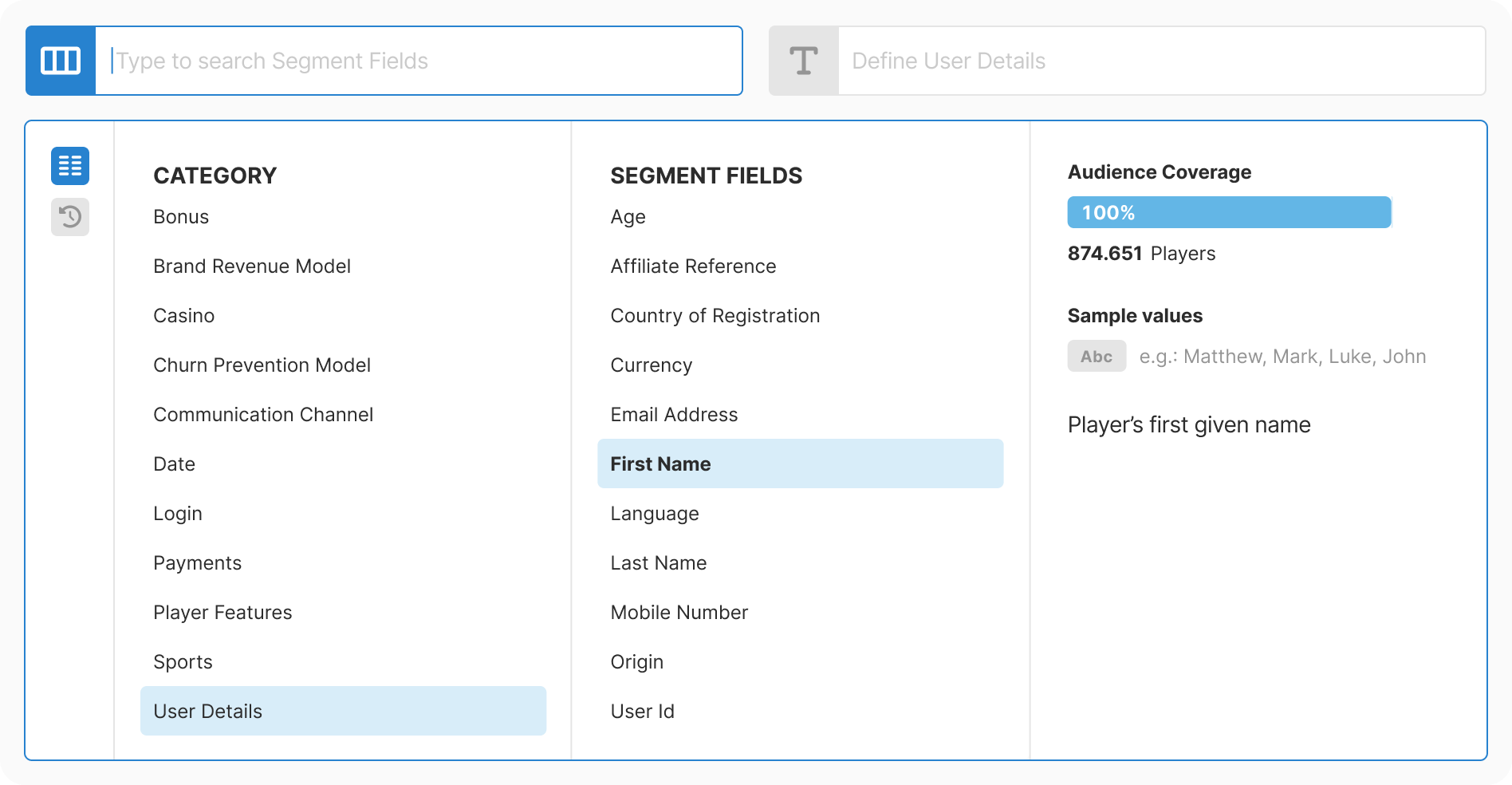
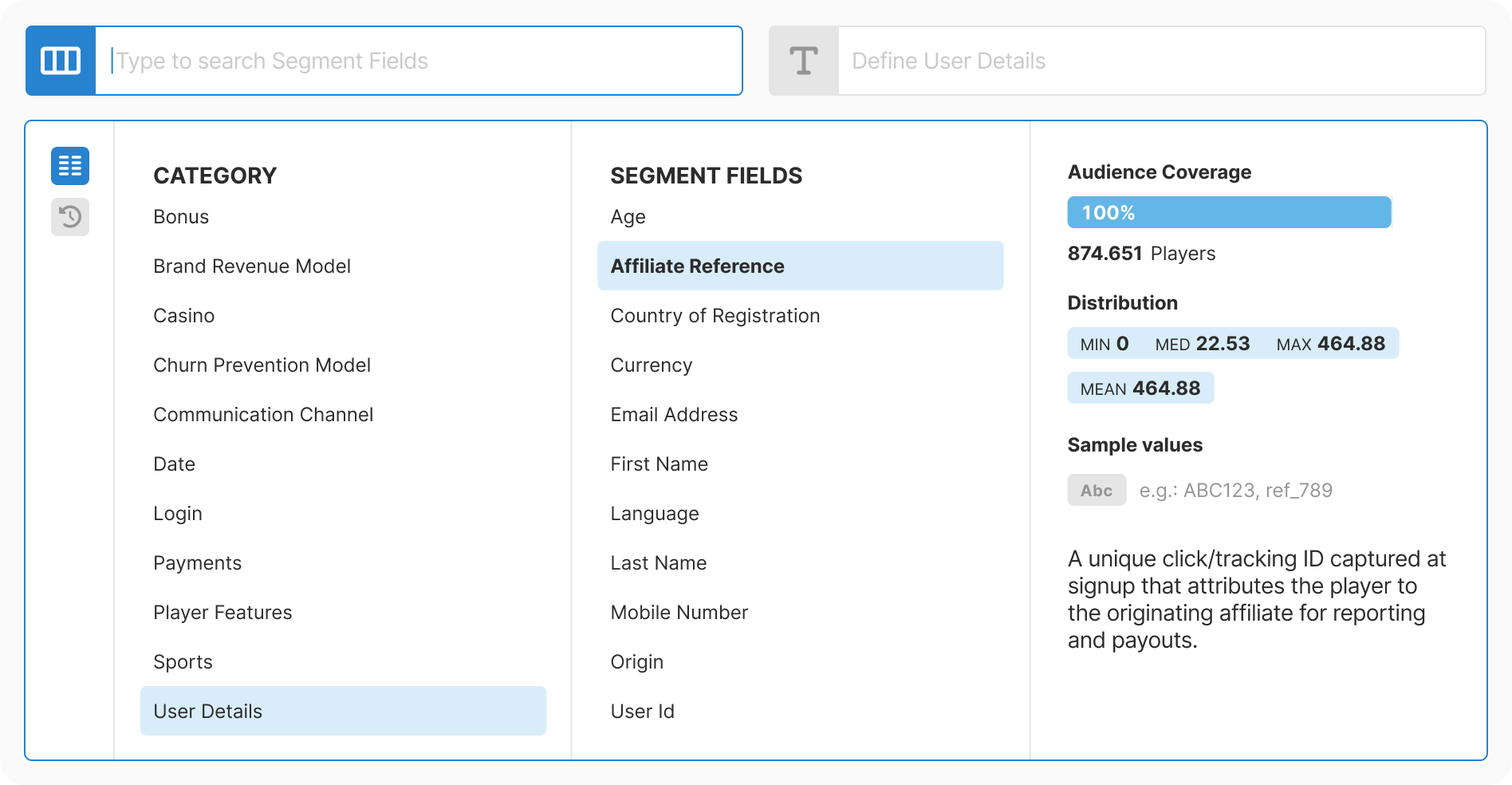
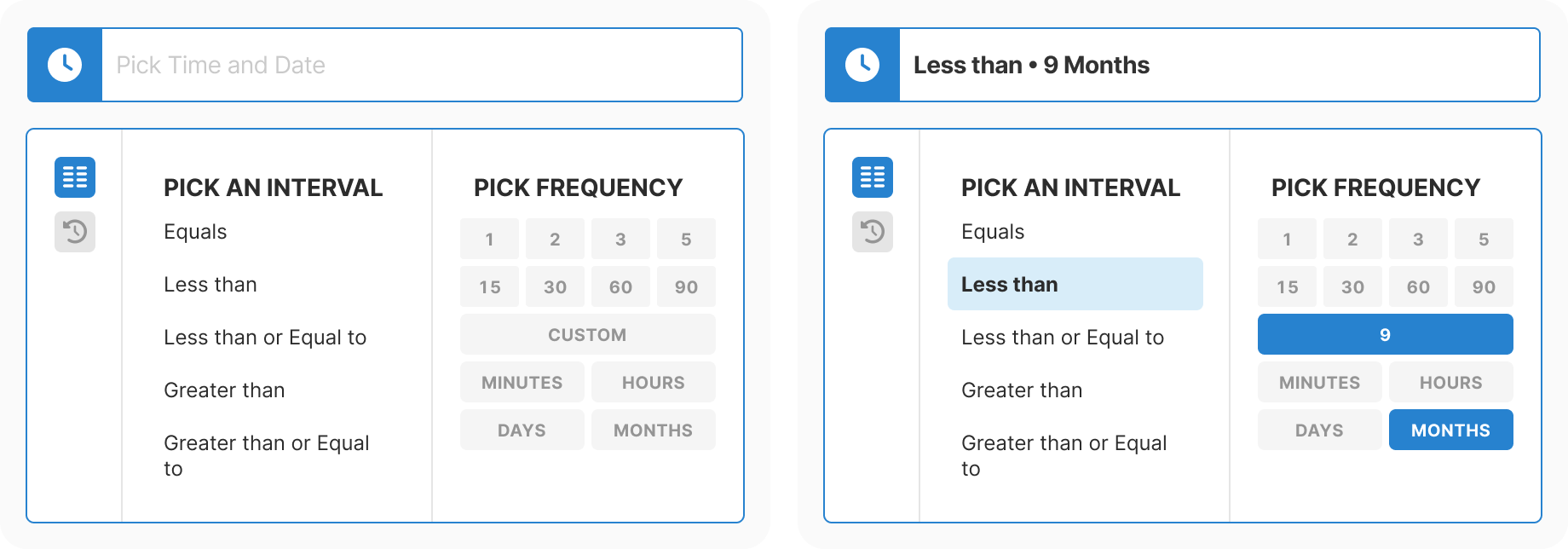
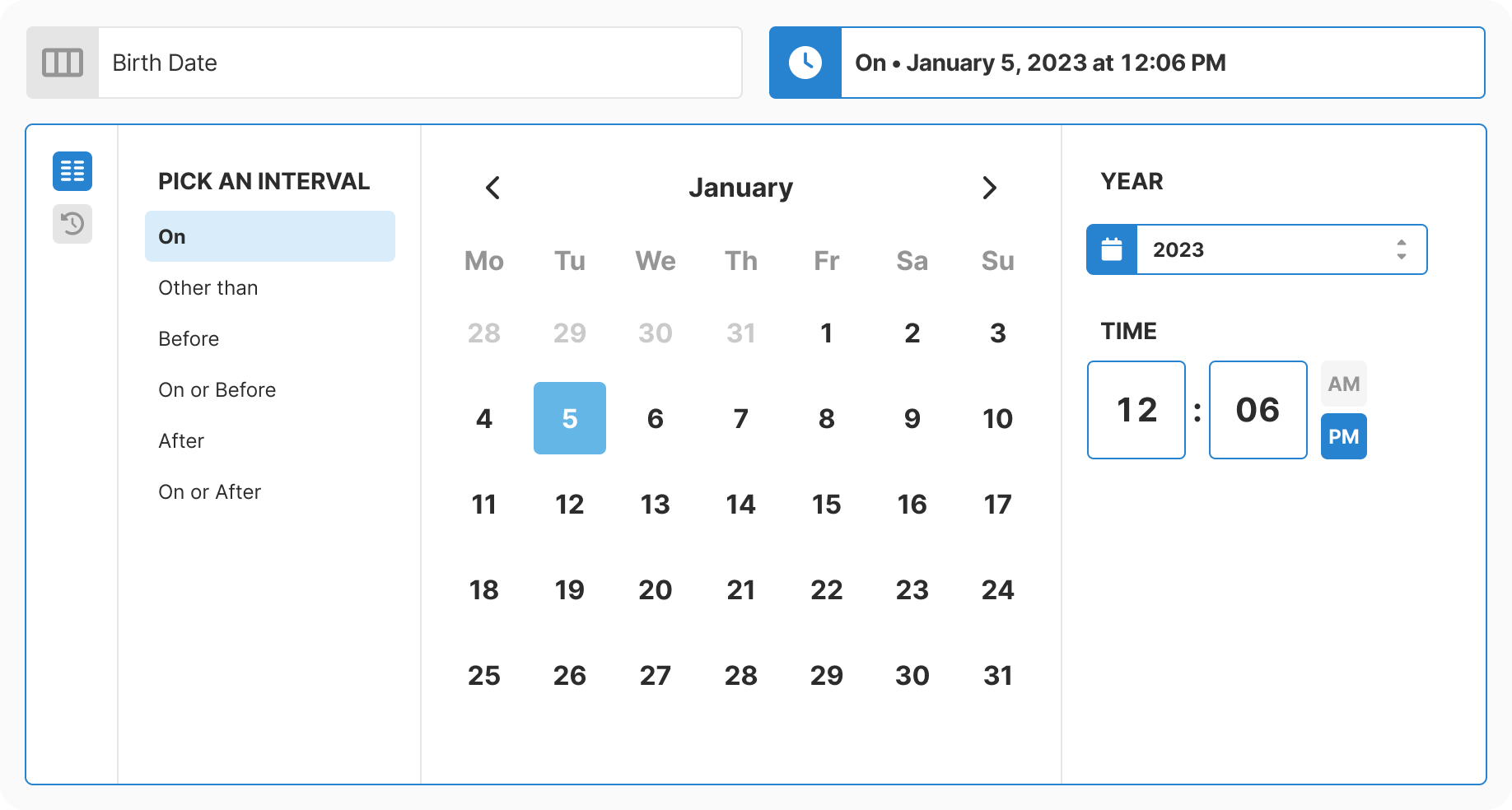
Design: Created progressive three-step flow with real-time context at each decision point. Removed all free-text inputs. Added type-aware controls for each data type.
Development: Built as reusable component with strict type contracts. Optimized for performance with virtualization and caching. Integrated analytics from day one.
Rollout: Simultaneous release across all touchpoints to avoid UX drift. Published documentation immediately. Ran partner enablement sessions.
Validation: Monitored adoption and error telemetry in production. Zero critical incidents. Pattern adopted by other teams as reference standard.